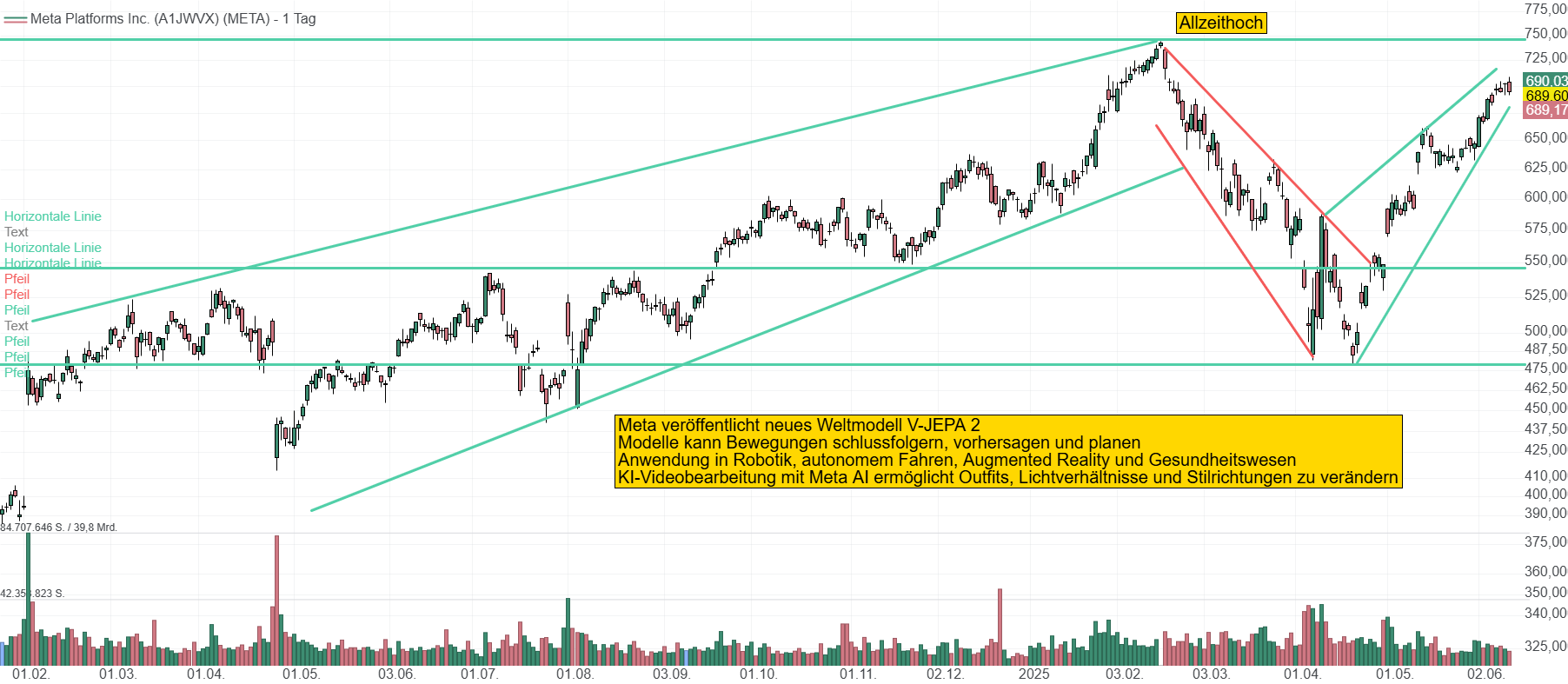
Mit der Vorstellung von V-JEPA 2 läutet Meta Platforms (META) eine neue Phase der KI-Entwicklung ein. Statt sich nur auf Sprache oder Text zu konzentrieren, zielt das Unternehmen mit seinem neuen Weltmodell auf etwas Grundsätzlicheres - das physikalische Denken. V-JEPA 2 soll Maschinen helfen, die reale Welt nicht nur visuell zu erfassen, sondern deren Gesetzmäßigkeiten zu begreifen und vorauszudenken, bevor gehandelt wird. Kombiniert mit neuen Tools zur KI-Videobearbeitung, die kreativen Nutzern ganz neue Ausdrucksmöglichkeiten bieten, zeigt Meta, wohin die Reise geht - zu einer KI, die sieht, versteht, plant – und zunehmend selbstständig agiert.
V-JEPA 2 - Ein neues KI-Modell, das denkt, bevor es handelt
Mit V-JEPA 2 stellt Meta ein neues Weltmodell vor, das einen bedeutenden Schritt auf dem Weg zur fortgeschrittenen maschinellen Intelligenz (Advanced Machine Intelligence, AMI) darstellt. Es handelt sich um ein KI-System, das in der Lage ist, nicht nur zu sehen, sondern auch physikalisch zu schlussfolgern, vorherzusagen und zu planen – ähnlich wie Menschen es instinktiv tun. V-JEPA 2 wurde mithilfe unzähliger Videos trainiert und lernte dabei, wie Objekte sich in der realen Welt bewegen, wie sie miteinander interagieren und was aus bestimmten Handlungen resultiert. Dadurch kann das Modell beispielsweise abschätzen, was passiert, wenn ein Roboter ein Glas schiebt oder einen Ball fallen lässt. Diese Fähigkeit, physikalische Szenarien in einem latenten Raum zu modellieren, ermöglicht KI-Agenten, "nachzudenken, bevor sie handeln" – ein wesentlicher Fortschritt gegenüber klassischen Sprachmodellen, die keine physische Welt verstehen.
Weltmodelle - Digitale Zwillinge der Realität
V-JEPA 2 gehört zur neuen Generation sogenannter Weltmodelle, die sich als digitaler Zwilling der Realität verstehen lassen. Im Gegensatz zu Sprachmodellen wie ChatGPT oder Gemini von Google geht es hier nicht um linguistisches Verständnis, sondern um das Verstehen von Raum, Zeit, Kausalität und physischer Interaktion. Diese Modelle sollen Maschinen helfen, sich in der realen Welt zu orientieren – ob in Form von Robotern, autonomen Fahrzeugen oder virtuellen Agenten. V-JEPA 2 analysiert nicht nur die sichtbare Welt, sondern arbeitet mit einer abstrakten, reduzierten Darstellung, dem sogenannten "latenten Raum", in der es Ursache-Wirkung-Beziehungen rekonstruiert und hypothetische Szenarien durchspielt. Die Anwendungen reichen von Robotik über Logistik bis zur Navigation in komplexen 3D-Umgebungen.
Technische Anwendungsbereiche - Von Robotern bis zu autonomen Fahrzeugen
V-JEPA 2 eröffnet technisch betrachtet neue Horizonte für eine Vielzahl von Branchen. In der Robotik etwa können Haushalts- und Industrieroboter dank des verbesserten physikalischen Verständnisses gezielter greifen, platzieren und navigieren. Autonome Fahrzeuge profitieren von der Fähigkeit des Modells, komplexe Verkehrssituationen präziser zu antizipieren und entsprechend zu reagieren. Auch im Bereich Augmented Reality verleiht V-JEPA 2 interaktiven Systemen ein realistischeres Raumgefühl, was die Immersion deutlich erhöht. In der Planung, Fertigung und im Gesundheitswesen ermöglicht die Technologie realitätsnahe Simulationen und den Einsatz digitaler Zwillinge. Darüber hinaus können Assistenzsysteme mit V-JEPA 2 nicht nur Sprache verarbeiten, sondern auch den physischen Kontext erkennen und verstehen – ein wichtiger Schritt hin zu intelligenteren, kontextsensiblen KI-Helfern. Meta veröffentlichte parallel zu V-JEPA 2 drei neue Benchmarks, die es der Forschungscommunity ermöglichen, die physikalische Schlussfolgerungskompetenz ihrer Modelle objektiv zu testen. Diese Tests sollen beurteilen, wie gut ein Modell erkennen kann, was mit einem Objekt geschieht, das sich außerhalb des Sichtfelds bewegt, verdeckt wird oder auf eine andere Weise verändert. Ziel ist es, Forschung und Entwicklung in Richtung praxisnaher, verständiger KI-Systeme zu beschleunigen.
KI-Videobearbeitung mit Meta AI ermöglicht Kreativität per Klick
Neben dem Weltmodell stellt Meta auch eine generative KI-Videobearbeitungsfunktion vor, die ab sofort in der Meta AI App, auf Meta.AI und in der Edits App verfügbar ist. Nutzer können mithilfe voreingestellter KI-Anweisungen etwa Outfits, Lichtverhältnisse, Stilrichtungen oder komplette Szenarien in ihren Videos verändern – ganz ohne Vorkenntnisse. Die Funktion basiert auf Metas Forschung zu Bild- und Videogenerierung im Bereich Make-A-Scene, Llama-Modelle, Movie Gen und ermöglicht eine einfache, intuitive Transformation von Videoinhalten. Ob Vintage-Comic-Look, Neon-Gaming-Stil oder verträumte Beleuchtung. Die Resultate wirken hochwertig, kreativ und unterhaltsam. Die Videos können direkt auf Facebook, Instagram oder in einem Discover-Feed geteilt werden.
Meta als Schrittmacher für KI und medienbasierte Intelligenz
Meta hat sich in der KI-Welt von einem reinen Social-Media-Konzern zu einem führenden Akteur in der Erforschung multimodaler KI entwickelt. Mit Investitionen in Höhe von mehreren Mrd. USD – etwa in Scale AI – und offenen Forschungsinitiativen wie LLaMA, V-JEPA oder Movie Gen verfolgt Meta seinen langfristigen Plan: die Verschmelzung von KI, Vision, Handlung und Interaktion. Weltmodelle wie V-JEPA 2 markieren einen strategischen Meilenstein, da sie nicht nur technische Leistungsfähigkeit zeigen, sondern auch praktisch einsetzbar sind – etwa in der Robotik, Automatisierung oder generativen Medienproduktion. Damit positioniert sich Meta als einer der Pioniere für fortgeschrittene maschinelle Intelligenz, deren Potenzial über bloße Textgenerierung weit hinausgeht – und das Fundament für die nächste Generation intelligenter Systeme legt.